by: Puneet Oberai & Christos Kalantzis
Overview
Astyanax is one of Netflix’s more popular OSS Projects. About a year ago, whenever we spoke with Cassandra users, Astyanax was considered the de facto Java Client library for Cassandra (C*) because of features such as connection pooling, intelligent load balancing between C* nodes as well as the Recipes.
With the advent of the new Java Driver from DataStax, which has incorporated some of the best Astyanax concepts, many in the community have been wondering if Astyanax is still relevant. They’ve also wondered why there hasn't been any major new release, or if Netflix is still using it?
This article is meant to address those questions. We will also share the findings we've discovered over the past few months while we've been investigating the new DataStax Java Driver. Finally, we will also share why Astyanax is still relevant in the Apache Cassandra Community and what our plans are for the project in 2014.
State of Affairs at Netflix
Netflix uses Astyanax as it's primary Cassandra client. Astyanax has a structured API which makes use of a fluent design that allows the consumer to perform complex queries with relative ease. The fluent design also makes it intuitive to explore the vast API. Complex queries supported by the API range from mixed batch mutations to sophisticated row range queries with composite columns.
Here is an example of a reverse range query on a composite column for a specified row.
keyspace.prepareQuery(CF)
.getRow("myRowKey")
.withColumnRange(new CompositeRangeBuilder()
.withPrefix("1st component of comp col")
.greaterThan("a")
.lessThan("z")
.reverse()
.limit(11)
.build())
.execute();
Astyanax also provides other layers of functionality on top of it's structured API.
- Astyanax recipes - these allow users to perform complex operations such as reading all rows from multiple token ranges, chunked object storage, optimistic distributed locking etc.
- Entity Mapper - this layer allows users to easily map their business logic entities to persistent objects in Cassandra.
The following diagram shows the overall architectural components of Astyanax. The library has been heavily adopted both within Netflix as well as externally. At Netflix many Cassandra users make heavy use of the api, recipes, entity layer and have also built their own DAOs on top of these layers, thus making Astyanax the common gateway to Cassandra.

DataStax Java Driver
Earlier this year, DataStax announced the release of their new Java Driver that uses the native protocol with CQL3. The new driver has good support for all the client functionality but also provides other benefits beyond that. Just to mention a few
- Out-of-the-box support for async operations over netty
- Cursors for pagination
- Query tracing when debugging
- Support for collections
- Built-in load balancing, retry policies etc.
Java Driver is a CQL3-based client and you should familiarize yourself with some key CQL3 concepts. Here are some good posts to read before you start playing with the driver.
1.0 and 2.0 releases
Note that the Java Driver 1.0 release was succeeded by a 2.0 release. The 2.0 release had some useful features and improvements over its predecessor such as cursor support for pagination and better handling of large mutation batches. However the 2.0 release also had a bunch of backwards-incompatible API changes. You need to consider the changes cited here by DataStax when upgrading from 1.0 release to the 2.0 release.
Integration
In the past few months we have been doing some R&D with the java driver and have a sample implementation of the structured Astyanax API using the native protocol driver. This integration leverages the best of both worlds (Astyanax and Java Driver) and we can in turn proxy the combined benefits to our consumers.
Note that we have implemented the Astyanax API which is compatible with the current thrift-based implementation. Our thrift-based driver is operational and still being supported. |

Here are some of the benefits based on our findings and integration work
Structured api with async support
You can now use the Astyanax async interface with all the structured APIs.
ListenableFuture<OperationResult<Row>> future = keyspace.prepareQuery(myCF).getRow("myRowKey").execAsync(); future.addListener( new Runnable() { ... }, myExecutor ); The overall benefit of using the async protocol is that one can multiplex more requests on the same connection to the Cassandra nodes. Request multiplexing on the same connection yields higher throughput for the same number of connections. |
However one still has to design their application with an async model for truly realizing the performance gains from this feature. With the async interface, calling code gets a future that gives a callback when the result is ready, thus “unblocking” the calling code. But if the caller just blocks on the future anyways, then the app will probably not benefit a whole lot from this feature.
Astyanax helps with prepared statement management
It is important to note that in order to use the native driver in a performant manner, one must make use of prepared statements. The thing that makes prepared statements performant is that they can be re-used and hence you pay the cost to “prepare” only once. However the management of prepared statements for different queries is left up to the app. Astyanax uses a structured query interface which enables it to intelligently manage prepared statements for consumer apps. More on this in the sections below on findings and caveats.
Astyanax provides a unified interface across multiple drivers
Note that since the Astyanax API is the lowest common denominator we decided to provide an alternate implementation of the API using an adaptor layer over Java Driver. Furthermore we have preserved the semantics of rows and columns as before irrespective of the driver being used underneath.
For certain commonly used schemas, CQL3 will treat unique columns as unique rows. When you read a row via Astyanax, it will always be a row regardless of the driver being used underneath. This gives consumers the freedom of choice when deciding what driver to use and even switch back and forth while still maintaining the same application logic, data model etc.
Overall Astyanax provides a performant, structured and driver-independent client that enables developers to focus efforts on other useful higher level abstractions in their applications.
JD 1.0 v/s 2.0
Initially we started with wrapping Java Driver 1.0 but then realized that it was lacking some critical features like the cursor support which made certain complicated range queries much harder and almost impractical to implement. Further we found compile-time incompatibilities between the 2 drivers and wanted to avoid writing multiple adaptors around multiple driver versions. Hence we decided to directly adopt the 2.0 release of the driver. This did cause significant re-work on the Astyanax side which also included a re-run of benchmarking tests for the driver. More on benchmark numbers below.
Migration path
Note that the 2.0 driver works only against C* 2.x clusters. Hence If you are directly using the Java Driver and if you are on a 1.x cluster, then you'd have to continue to use the 1.0 release while you upgrade your cluster to 2.x. Once this is done, you can then switch to the 2.0 release after making code changes to your app due to the non backwards compatibility between the 2 releases of the driver.
If you are currently using Astyanax and want to use the new native protocol based driver, then you should stay with the thrift-based driver until you upgrade your cluster to 2.x and only then switch to the new driver based impl. The Astyanax adaptor over java driver implements the same Astyanax API, hence we don't anticipate major code changes when switching over.
Note that even though the api is backwards compatible with the new release, this is a beta release and there are caveats to note here. More on this below.
Caveats / Findings
Note that in the interest of brevity, the following is not an exhaustive list of all our findings. We will have the complete list available on the Astyanax wiki soon.
Performance characteristics
Basic setup
We deployed a single 2.0 cluster with 6 nodes (m2.4xlarge). We used the bare min config with a replication factor of 3. The goal here was NOT to benchmark the 2.0 cluster performance but compare the different drivers using the same client setup.
We deployed a simple client that wrapped Astyanax and repeatedly issued simple queries in a multi-threaded setup. The client was operated in 3 modes.
- The standard Astyanax client that uses the thrift driver underneath
- The standard Java Driver released by DataStax.
- Astyanax over Java Driver - a limited implementation of the Astyanax interface that uses the Java Driver underneath instead of thrift.
The client was run concurrently in all 3 modes against the same 2.0 cluster using 3 separate ASGs with the same instance type (m2.xlarge), no of instances and no of client threads.
Here are the keyspace and column family settings
CREATE KEYSPACE astyanaxperf WITH replication = { 'class': 'NetworkTopologyStrategy', 'us-east': '3' }; USE astyanaxperf; CREATE TABLE test1 ( key bigint, column1 int, value text, PRIMARY KEY (key, column1) ) WITH COMPACT STORAGE AND bloom_filter_fp_chance=0.010000 AND caching='KEYS_ONLY' AND comment='' AND dclocal_read_repair_chance=0.000000 AND gc_grace_seconds=864000 AND index_interval=128 AND read_repair_chance=0.100000 AND replicate_on_write='true' AND populate_io_cache_on_flush='false' AND default_time_to_live=0 AND speculative_retry='99.0PERCENTILE' AND memtable_flush_period_in_ms=0 AND compaction={'class': 'SizeTieredCompactionStrategy'} AND compression={'sstable_compression': 'SnappyCompressor'}; |
Other settings included using 8 connections to the cluster from each client (aws instance) and consistency level was ONE for both reads and writes.
Overall we found that java driver (with prepared statements) was roughly comparable to the thrift-based driver with the latter getting about 5-10% more throughput especially for large batch mutations.
Batch Mutations
There is about a 5-10% deviation between thrift and the java driver, where thrift was faster than java driver.![]()

Single Row Reads
Variation between reads was lesser (2%-5%).![]()

Using Prepared Statements
Note that when using Java Driver one must use prepared statements for better performance. Here are examples of using queries both with and without prepared statements.
Regular query
while (!perfTest.stopped()) { String query = "select * from astyanaxperf.test1 where key=" + random.nextInt(); ResultSet resultSet = session.executeQuery(query); parseResultSet(resultSet); } |
prepared statement
String query = "select * from astyanaxperf.test1 where key=?"; // Cache the prepared statement for later re-use PreparedStatement pStatement = session.prepareQuery(query); while (!perfTest.stopped()) { // Build exact query from prepared statement BoundStatement bStatement = new BoundStatement(pStatement); bStatement.bind(random.nextInt()); ResultSet resultSet = session.executeQuery(bStatement); parseResultSet(resultSet); } |
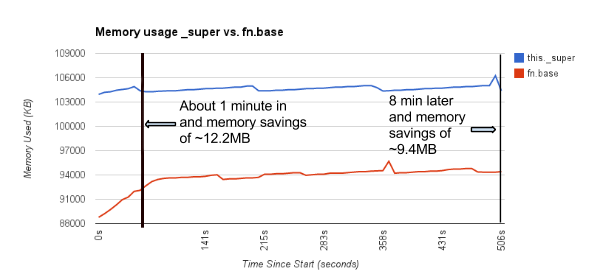
As you can see below, the performance difference between these 2 blocks of code is significant, hence users are encouraged on using prepared statements when using either Java Driver or the Astyanax adaptor over Java Driver. ![]()

Prepared statements require management
Note that prepared statements (by design) need to be managed by the application that uses Java Driver. In the examples above, you can see that the prepared statement needs to be supplied back to driver for re-use (and hence better performance), which means that the caller has to manage this statement. When client apps build sophisticated DAOs, they generally make use of several queries and hence need to maintain the mapping between their use cases (query patterns) and the corresponding prepared statements. This will complicate the DAO implementations.
This is where Astyanax can help. Astyanax uses a fluent yet structured query syntax. The structured API design makes it feasible to construct a query signature for each query. The query signature can be used by Astyanax to detect recurring queries with similar structure (signature) and hence re-use the corresponding prepared statement. Hence Astyanax users can get automatic prepared statement management for free.
Here are examples on how to do this.
Writes
MutationBatch m = keyspace.prepareMutationBatch(); m.withRow( myCF, rowKey) .useCaching() // tell Astyanax to reuse prepared statements .addColumn( columnName, columnValue ) .execute(); |
Reads
pStmt = keyspace.prepareQuery( myCF ) .useCaching(true) .withRow( myRowKey ) .execute(); |
The catch with prepared-statements management!
An important caveat to note here is that prepared statements work well when your queries are highly cacheable, which means that your queries have the same signature. For writes this means that if you are adding, updating, deleting columns with different timestamps and TTLs then you can't leverage prepared statements since there is no "cacheability" in those queries. If you want the mutation batches to be highly cacheable, then you must use the same TTLs and timestamps when re-using prepared statements for subsequent batches.
Similarly for reads, you can't prepare a statement by doing a row query and then reuse that statement for a subsequent row query that also has a column slice component to it, since the underlying query structure is actually different.
Here is an example to illustrate my point
// Select a row with a column slice specification (column range query) select * from test1 where key = ? and column1 > ?; // is very different from a similar column slice query select * from test1 where key = ? and column1 > ? and column1 < ?; // Hence both these queries have different signatures and hence need their own prepared statements. Hence use the automatic statement management feature in Astyanax with caution. Inspect your table schema and your query patterns. When using queries with different patterns, turn caching OFF. Rows v/s ColumnsIn CQL3 columns can be rows as well depending on your column family schema. Here is a simple example. Say that you have a simple table with the following schema. Key Validator: INT_TYPE Column Comparator: INT_TYPE Default Validator : UTF8_TYPE Here is what data would look like at the storage level (example data)  |
In Astyanax, rows and columns directly map to this structure. i.e Astyanax rows directly map to storage rows.
But in CQL3 the same CF has a clustering key that corresponds to your column comparator. Hence unique columns will appear as distinct rows.![]()

If you are migrating your app from using a thrift based driver (such as Astyanax) to the new java driver, then your application business logic must account for this.
In order to keep things consistent in Astyanax and also avoid a lot of confusion, we have preserved the original semantics for rows and columns. i.e Astyanax's view of rows and columns is the same regardless of the driver being used underneath. This approach helps application owners keep their biz logic and DAO models the same and avoids a re-write of all the numerous DAOs at Netflix.
Summary - Astyanax in 2014
We have been quiet on the Astyanax front for a while. However, I’m sure based on this article you finally understand why. Astyanax still provides value to the Apache Cassandra (C*) community. Even with the integration of the DataStax Java Driver you still get a Structured API with async support, help with prepared statement management, backward compatibility within your existing Cassandra applications and a unified interface across multiple drivers. According to our findings above, in some cases, the continued use of the current Astyanax library will provide better performance than the Java Driver alone.
Here is a quote from Patrick McFadin, Chief Evangelist for Apache Cassandra:
“ Once again Netflix has shown it's leadership in the community by creating incredible tools for Apache Cassandra. Netflix and DataStax provide an excellent example of when working together for the benefit of users, amazing things can happen. I love where Astyanax is headed with it's rich API and great recipes. This type of collaboration is what I feel is the best part of Open Source Software.”
A Beta release of Astyanax will be released in mid-January 2014. This new release will contain our integration with Java Driver 2.0 and all the features mentioned in this article.
Netflix believes very strongly in the Astyanax Project and will continue to work with the Apache Cassandra Community to move it forward. If you would like to contribute to the project, feel free to submit code to the Astyanax project, open issues or even apply at jobs.netflix.com.