It’s 2 a.m. and half of our reliability team is online searching for the root cause of why Netflix streaming isn’t working. None of our systems are obviously broken, but something is amiss and we’re not seeing it. After an hour of searching we realize there is one rogue server in our farm causing the problem. We missed it amongst the thousands of other servers because we were looking for a clearly visible problem, not an insidious deviant.
In Netflix’s Marvel’s Daredevil, Matt Murdock uses his heightened senses to detect when a person’s actions are abnormal. This allows him to go beyond what others see to determine the non-obvious, like when someone is lying. Similar to this, we set out to build a system that could look beyond the obvious and find the subtle differences in servers that could be causing production problems. In this post we’ll describe our automated outlier detection and remediation for unhealthy servers that has saved us from countless hours of late-night heroics.
Shadows in the Glass
The Netflix service currently runs on tens of thousands of servers; typically less than one percent of those become unhealthy. For example, a server’s network performance might degrade and cause elevated request processing latency. The unhealthy server will respond to health checks and show normal system-level metrics but still be operating in a suboptimal state.
A slow or unhealthy server is worse than a down server because its effects can be small enough to stay within the tolerances of our monitoring system and be overlooked by an on-call engineer scanning through graphs, but still have a customer impact and drive calls to customer service. Somewhere out there a few unhealthy servers lurk among thousands of healthy ones.
Image may be NSFW.
Clik here to view.
Clik here to view.
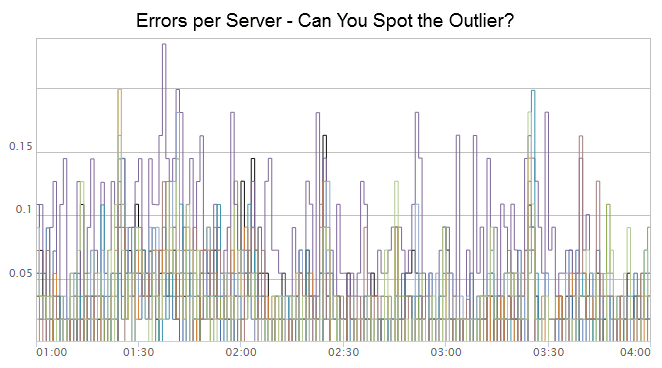
The purple line in the graph above has an error rate higher than the norm. All other servers have spikes but drop back down to zero, whereas the purple line consistently stays above all others. Would you be able to spot this as an outlier? Is there a way to use time series data to automatically find these outliers?
A very unhealthy server can easily be detected by a threshold alert. But threshold alerts require wide tolerances to account for spikes in the data. They also require periodic tuning to account for changes in access patterns and volume. A key step towards our goal of improving reliability is to automate the detection of servers that are operating in a degraded state but not bad enough to be detected by a threshold alert.
Image may be NSFW.
Clik here to view.
Clik here to view.

Finding a Rabbit in a Snowstorm
To solve this problem we use cluster analysis, which is an unsupervised machine learning technique. The goal of cluster analysis is to group objects in such a way that objects in the same cluster are more similar to each other than those in other clusters. The advantage of using an unsupervised technique is that we do not need to have labeled data, i.e., we do not need to create a training dataset that contains examples of outliers. While there are many different clustering algorithms, each with their own tradeoffs, we use Density-Based Spatial Clustering of Applications with Noise (DBSCAN) to determine which servers are not performing like the others.
How DBSCAN Works
DBSCAN is a clustering algorithm originally proposed in 1996 by Martin Ester, Hans-Peter Kriegel, Jörg Sander and Xiaowei Xu. This technique iterates over a set of points and marks as clusters points that are in regions with many nearby neighbors, while marking those in lower density regions as outliers. Conceptually, if a particular point belongs to a cluster it should be near lots of other points as measured by some distance function. For an excellent visual representation of this see Naftali Harris’ blog post on visualizing DBSCAN clustering.
How We Use DBSCAN
To use server outlier detection, a service owner specifies a metric which will be monitored for outliers. Using this metric we collect a window of data from Atlas, our primary time series telemetry platform. This window is then passed to the DBSCAN algorithm, which returns the set of servers considered outliers. For example, the image below shows the input into the DBSCAN algorithm; the red highlighted area is the current window of data:
Image may be NSFW.
Clik here to view.
Clik here to view.

In addition to specifying the metric to observe, a service owner specifies the minimum duration before a deviating server is considered an outlier. After detection, control is handed off to our alerting system that can take any number of actions including:
- email or page a service owner
- remove the server from service without terminating it
- gather forensic data for investigation
- terminate the server to allow the auto scaling group to replace it
Parameter Selection
DBSCAN requires two input parameters for configuration; a distance measure and a minimum cluster size. However, service owners do not want to think about finding the right combination of parameters to make the algorithm effective in identifying outliers. We simplify this by having service owners define the current number of outliers, if there are any, at configuration time. Based on this knowledge, the distance and minimum cluster size parameters are selected using simulated annealing. This approach has been effective in reducing the complexity of setting up outlier detection and has facilitated adoption across multiple teams; service owners do not need to concern themselves with the details of the algorithm.
Into the Ring
To assess the effectiveness of our technique we evaluated results from a production service with outlier detection enabled. Using one week’s worth of data, we manually determined if a server should have been classified as an outlier and remediated. We then cross-referenced these servers with the results from our outlier detection system. From this, we were able to calculate a set of evaluation metrics including precision, recall, and f-score:
Server Count | Precision | Recall | F-score |
1960 | 93% | 87% | 90% |
These results illustrate that we cannot perfectly distill outliers in our environment but we can get close. An imperfect solution is entirely acceptable in our cloud environment because the cost of an individual mistake is relatively low. Erroneously terminating a server or pulling one out of service has little to no impact because it will be immediately replaced with a fresh server. When using statistical solutions for auto remediation we must be comfortable knowing that the system will not be entirely accurate; an imperfect solution is preferable to no solution at all.
The Ones We Leave Behind
Our current implementation is based on a mini-batch approach where we collect a window of data and use this to make a decision. Compared to a real-time approach, this has the drawback that outlier detection time is tightly coupled to window size: too small and you’re subject to noise, too big and your detection time suffers. Improved approaches could leverage advancements in real-time stream processing frameworks such as Mantis (Netflix's Event Stream Processing System) and Apache Spark Streaming. Furthermore, significant work has been conducted in the areas of data stream mining and online machine learning. We encourage anyone looking to implement such a system to consider using online techniques to minimize time to detect.
Parameter selection could be further improved with two additional services: a data tagger for compiling training datasets and a model server capable of scoring the performance of a model and retraining the model based on an appropriate dataset from the tagger. We’re currently tackling these problems to allow service owners to bootstrap their outlier detection by tagging data (a domain in which they are intimately familiar) and then computing the DBSCAN parameters (a domain that is likely foreign) using a bayesian parameter selection technique to optimize the score of the parameters against the training dataset.
World on Fire
As Netflix’s cloud infrastructure increases in scale, automating operational decisions enables us to improve availability and reduce human intervention. Just as Daredevil uses his suit to amplify his fighting abilities, we can use machine learning and automated responses to enhance the effectiveness of our site reliability engineers and on-call developers. Server outlier detection is one example of such automation, other examples include Scryer and Hystrix. We are exploring additional areas to automate such as:
- Analysis and tuning of service thresholds and timeouts
- Automated canary analysis
- Shifting traffic in response to region-wide outages
- Automated performance tests that tune our autoscaling rules
These are just a few example of steps towards building self-healing systems of immense scale. If you would like to join us in tackling these kinds of challenges, we arehiring!